Secrecy and Language Models
Here we explore the question of whether or not two parties, one with an input and another with a model, can keep secrets from each other while effectively making use of that model. Practical methods for performing language modeling such that the provider does not share most of their language modeling information and the user shares none of their input information are detailed.
Introduction
It is common today (2026) for many individuals and organizations to send sensitive and otherwise confidential information to language models providers in order to enjoy the benefits of these models. The nature of language modeling means that these individuals and organizations must place a great deal of trust in the language model provider: although information may be encrypted during transit, the provider must be able to obtain an unencrypted form of the user’s data in order to generate useful model outputs. There is nothing in principle from preventing these providers from obtaining the information fed to their models because of this. A short while ago it was more or less inconcievable that such information would be shared in so unsecure a format. These observations motivate the central question of this work: can a language model user with an input keep the information content of that input confidential and still make use of the provider’s model, while at the same time can the provider keep their model secret from the user?
The primary difficulty here lies in the necessity that the model gives a useful output to any given input. This precludes approaches to this problem where a user encrypts the input but does not decrypt before the language model observes the input, or where a user injects noise into an input to obfuscate it. It is trivial to give a secrecy system that simply corrupts or removes sensitive input information, but as this clearly changes the behavior of the model’s output it is undesirable to do so.
One approach to the problem of security and language model inputs is hardware encryption guarantees, which for example nvidia offers for newer datacenter GPUs. This may be considered to be an unsatisfactory solution to this problem for a number of reasons, but most of all because the user cannot actually verify that the ecryption is in place without accessing the provider’s secrets (the model) and thus simply shifts the burden of trust onto yet another element that is controlled by the provider.
We exlore this problem with the assumption that the user and provider to undergo successful language modeling without some degree of cooperation, and focus on the particular case where a provider is willing to share some of their model’s information with the user but the user seeks to minimize the information they send to the provider.
Secrecy in LLMs
The question of how a provider and user would minimize the amount of information they would necessarily share with one another begins with an easier question: is it possible to perform language modeling in this scenario when the provider simply does not share all the model’s information, and where the user likewise does not reveal all their information? Without further investigation the answer to this question can be determined as ‘yes’, as this follows from the results of previous work finding that language models are functionally non-invertible, meaning that one cannot train a model using a reasonable amount of compute to invert the last hidden layer’s last token embedding to regenerate the input that was fed to the model to generate the embedding in the first place.
A system by which neither provider or user has access to all model and input information but always receives the correct next token is as follows: first a provider shares all layers of their model except the language modeling head to the user, who then performs a forward pass on those layers to get the last token last hidden layer activations, and then sends those to the provider to recieve the next token. The results in the above paper imply that the provider cannot uniquely identify more that around 7\% of the tokens the embedding corresponds to, such that the exact information it contains remains secret and likewise the language modeling head layer remains secret from the user.
This is notably not a very good secrecy system: with enough inputs the user will be able to closely approximate the provider’s language modeling head transformation assuming that it is a single linear layer, and likewise although the provider cannot identify exact tokens the embedding still contains some useful input information. A natural question to ask is whether or not the provider could simply send fewer layers to the user and thus retain more model information without decreasing next token accuracy.
This motivates the following question: what is necessary for language modeling secrecy in this scenario? We make the following additional assumptions, which arguably best reflect a most realistic scenario:
- The provider is able to guess the method by which the user encodes their message, even if they cannot determine what exactly that message is. In particular, this means that if the user has multiple approaches for secrecy encodings and can choose any of these, the provider ‘knows’ which one the user takes.
- The provider has available a much larger amount of compute by which they can attempt to decode incoming messages than the user has to generate these messages.
- The provider is willing to make public a portion of their model.
- The user is capable of modifying any portion of the provider’s model they receive.
- The provider is able to guess the general language corpus that is representative of the user’s secret messages, and in particular the provider can access an unlimited number of training examples from an in-distribution dataset of the user’s messages.
- The provider can collect all information the user sends and use this for decoding purposes.
With these assumptions, secrecy with respect to language modeling can be defined analagously to public key cryptography: for a secret message to remain secret, the user must be able to encode (embed) the message using a one-way function that is easy to compute and relatively easy to train, but is very difficult or impossible to invert. The added difficulty here is that this function must not interfere with next token prediction, whereas the usual public key algorithms applied to token integers certainly would. We define this one-way function as an ‘effectively noninvertible’ function, one that cannot be inverted over the input space by a machine learning model (a transformer) even when a very large amount of data and compute is applied.
Theory: Secrecy and Invertibility
In our setting a user sends an encoded sequence to a provider who must be able to use that encoding for next token prediction while at the same time be unable to decipher its secrets. We therefore seek a one-way function from the secret messages $m \in M$ to the encoding such that the user is able to easily encode but the provider cannot decode, with the notable addendum that this one-way function must not prevent accurate next token prediction. Equivalent to the notion of a one-way function here is an effectively non-invertible one, where `effective’ denotes that for a given compute budget one cannot find a inversion function over that function’s domain, regardless of whether or not the function is strictly invertible or not (surjective and injective).
In the context of secrecy models, perfect secrecy requires that the model be expressed as a non-invertibile (more precisely non-injective) function that mixes a sufficiently large input space. We examine the first quality before proceeding to the second. A non-injective is one in which maps many distinct inputs to one single output. As currently constructed, language models are highly non-invertible (composed of many layers of non-invertible transfomrations) and fulfill this criteria almost trivially, but in the sense of next token prediction these models are also funcitonally non-invertible, as ealier mentioned, because one cannot typically regenerate the input sequence of tokens given a vector sufficient to map to the output (the last hidden layer of the last token). The likelihood of invertibility in this functional sense drops precipitously as the number of tokens in th einput sequence increases as the relative amount of information present in the last token’s last hidden layer decreases relative to the input’s total information.
As we shall see on this page although transformers are strictly non-invertible next token prediction language models are functionally invertible if hidden layers from all tokens are supplied to a decoder. As a full-input embedding must be given for the provider to keep secret more than just the language modeling head transformation, this paradigm is particularly important for the following discussion of applications.
Perfect Secrecy
After Shannon first consider the case of perfect secrecy, defined as where the probability distribution of a message over all potential messages is unchanged after one recieves an encryption of that message. We ignore the information yielded by the model’s prediction of the next token, as for certain architectures the provider would not have this information either.
In the classical sense, a message can be encrypted using a key at least as large as the message itself such that the number of encryptions is at least as large as the number of messages in order to provide perfect secrecy where the probability that a message has identity $M$ is unchanged if we are given the encoding of that message, $E$, or in symbols $P(M) = P_E(M)$ and which by Bayes theorem is equal to $P(E) = P_M(E)$. An example of perfect secrecy where $\vert M \vert = \vert E \vert = n$ was given by Shannon as follows: for encryption method $T$ mapping messages $M$ to encodings $E$, where $n$ messages are indexed $M_j \in { M_0, M_1, …, M_n }$ and similarly $E_s \in { E_0, E_1, …, E_n }$ and $T_i \in { T_0, T_1, …, T_n }$ we then have
\[T_iM_j = E_s\]with $s = i + j \pmod n$, this results in $P(E) = P_M(E) = 1/n$ fulfilling the condition of perfect secrecy.
We must adapt this theory to use with the language modeling scenario defined above because ciphering via $T$ must be restricted to generate encodings $E_s$ that are themselves useful natural language token sequences. We define a `useful’ encoding as one that yields the same next token (or next token probability distribution for sampled models) when fed to a language model as the original message $M_j$. The language model $\theta$ performs a transformation of potential input sequences $a$ to a single output token $b$, denoted as $b = O(a, \theta)$, which in the context of a perfect secrecy system can be represented as follows:
\[O(T_iM_j, \theta) = O(E_s, \theta)\]It is almost always safe to say that many distinct $b$ are mapped to one $a$ (which is certainly the case for natural language) such that $O: a \to b$ performs a non-invertible mapping. To create a perfect secrecy system, we proceed as follows: first for any given message $m$ we assemble a (potentially infinite) set of equivalent messages $M_j$ such that for all $k, l$ we have $O(M_k, \theta) = O(M_l, \theta), k \neq l$, then we map to an encoding via $T_i: M_j \to E_s$ ($E_s$ is also an element of $M$ by definition) to receive our encoding, which yields the same output when fed to the provider’s model but reveals nothing about the actual input sequence. Conceptually this procedure may be stated as follows: if we can map our secret message to the set of all messages that yield the same next token when fed to a provider’s model, we can simply swap our phrase for a randomly chosen element of this set and reveal nothing about our message assuming that the set is very large (typically it is infinitely large ignoring context window limitations). The two necessary elements for this procedure are non-invertibility of the model (so that the set $M$ is larger than 1) and input mixing (so that $m$ can be swapped with $M_j$).
There is a substantial practical problem with this approach, however: if we were to find a function $F$ to generate the set $M$ that results in the same next token as our message $m$, we end up with a function that infers the same next token as the provider’s model. This means that the user would not actually need to use the provider’s model at all, and the provider’s information is effectively obtained by the user. This difficulty may be circumvented if the user instead obtains a causal language modeling (next token prediction) loss gradient from the provider, where the gradient is backpropegated through the provider’s model portion and can be used to back-propegate through the user’s model portion and inform how the user’s model can be updated while still remaining accurate with respect to next token prediction.
We now turn to practical secrecy methods that do not require a recapitulation of the provider’s model portion, assuming that the provider gives the appropriate gradients to the user when requested.
Practical Secrecy Defined
Practical secrecy for the user/provider language modeling paradigm may be defined as follows: can the user and provider share minimal information with each other while undergoing successful modeling, where the provider cannot realistically be expected to recover the user’s information given the compute they may have access to?
Before directly addressing this question, we can answer a simpler one: assuming that the provider has no compute or any other codebreaking method, can user and provider exchange minimal information and succeed in their modeling? The answer is yes, and one method that fulfills this criteria is as follows: first the provider sends the user a certain number of layers, say 1/4 or 1/2, of their model, secondly the user performs gradient descent on an initially random input in order to match the output of the last layer sent to the output of their secret message, and then they send this transformed input (actually the embedding of this input) to the provider instead of their message. Previous work has shown that such generated embeddings essentially never match the input that one uses to generate the target output as long as the target is not in the first few model layers. The input generation process is conditioned on a random starting point that depends on the seed one uses, such that for any message there are many (infinite) generated inputs that all yield the correct next token.
For an example, suppose we had the following secret message:
This is a secret message, not to be shared with anyone ever. The contents of this message are so obfuscated, so unknowable, that no one will ever be able to find what they are. The message is: The true identity of Satoshi Nakamoto is Spongebob Squarepants. End Message.
for a small 16-layer transformer model trained for next token prediction on FineWeb, if we perform this input generation procedure with three different random seeds (random initial states) we generate embeddings that map to the following tokens:
sign所所Batelizeomanip welt摄bebby Sob.ăng bby ofainathiselize inopleabweanik andOf of crest andeach.ofchina服obleoot Caldwellbyculo liesbybyAppearbyossal服ieuxof/original ofelize_ABI район/masterhaltainaainaoleonferenceselizeampa娘elize
sign所所 Carryelize(ns welt spiralRVby Sobelixăng bby ofainathiselize in висabweanik andOf of and andeach.of Zukoot visitorongsTo(nsbyculo易bybyAppearbyoyal服ieuxờiifth ofelizearchyspath/masterhaltainailtonoleonendoza"},ampa娘 cue
所`.`elizeapiro welt kRVяти Sob.ăng belize ofainathiselize in_soabwein andOf ofяб andeach.of ZukIobleongsTo Caldwellbyculo is andbyisetbyoyalidgeieuxofifth ofelizearchyspath khaltainailtonoleonferenceselizeampa娘 b
which are clearly distinct although they do contain a somewhat similar subset of input tokens, and in no way resemble the secret message.
Now the more difficult question: can user and provider exchange minimal information for successful modeling assuming that the provider attempts to recover the user’s input information? In an earlier section we saw if the provider is willing to share nearly all of the model with the user, and the user accepts that the provider will be able to identify around 7% of their input tokens, then the answer is yes. But it is unlikely that a provider would consent to share nearly all of their model with the user as is necessary in that method, nor is it likely that a user would be happy with only around 93% secrecy.
The difficulty here is that if the provider wishes to withold most of their model, and if we assume the provider uses a transformer model, the user must supply not just the last token’s last hidden layer but all token’s nth hidden layer embeddings to the provider. For causal transformers doing so results in a practically invertible system: we can train a decoder to take the output of all tokens of the user’s portion of the model and regenerate the input sequence, which is notably not the case if a single token’s embedding is used.
It turns out that if the provider expends some compute and effort to decipher the obfuscated inputs given by the gradient descent method above, they can determine the original message without too much trouble. The intuition here is that although many inputs map to one output, the inputs generated above are never actually found in the training dataset and thus a trained model can simply map these back to the corresponding real inputs. An inversion decoder trained to invert a language model’s encoding turns out to be sufficient to decode these obfuscated inputs, and this decoder is not difficult to train in terms of compute or data required.
How then can we attempt to approach practical secrecy in our language modeling scenario? To do so, we take inspiration from public key secrecy methods: these assume that ‘Alice’ creates a public and private key pair, send this publically to Bob, ‘Bob’ then uses the key to encrypt their message and then sends the encryption to Alice. An observer with the public key only cannot be expected to decrypt the encrypted message because the public key is assumed to be a one-way function, meaning one that is computationally easy to perform but difficult to invert. The private key of this pair is essentially the inversion, and must be kept secret.
The insight that secrecy can be equated with noninvertibility is central to this work, and we will later show that one can design an encoder so that (all) token hidden layer outputs of this encoder together are effectively noninvertible, even if the provider knows exactly how the client trained the encoder in all aspects except for the precise secret tag ‘key’ they used to generate the message. The resulting noninvertible embedding must then be processed by the client’s decoder and then the output of that decoder must be ‘decrypted’ by the client in some way locally. After examining approaches that did not offer secrecy, we show that this approach does.
Selecting embeddings from multiple encoders does not impart secrecy
Before turning to approaches involving model modification via gradient descent, it is first worth examining if secrecy can be obtained by simply using more than one encoder. The idea here is straightforward: if one were able to train a decoder to make use of embeddings from two separate encoders, each trained on different datasets, then an inverter for each model would fail on the embeddings from the other model. In particular, if one could mix embeddings per token for a sequence of size $n$, for two encoders there are $2^n$ possible sequences of identities for these embeddings. This number becomes much to large for anyone to guess and check which embeddings belonged to which model, and may be hoped to provide secrecy.
Can a decoder be trained to use sequences of randomly selected embeddings from substantially different causal language models, say one trained on FineWeb and one trained on FineMath? It turns out that training a decoder to do so is not particularly difficult, and reaches near-single model causal loss with less effort than required to train the model in the first place.
But what is required for a decoder to be able to use embeddings from two distinct encoders in a sequence? To accurately predict next tokens, a decoder would have to be able to accurately guess identity of each embedding with respect to which encoder it is likely to originate from, if the embeddings were sufficiently distinct. This apparently being the case, could a single inversion model be trained to perform the same embedding identity guessing procedure in order to invert the random embedding sequence?
The answer is yes, and it is not difficult for an inversion model to learn to invert random sequences of embeddings from distinct models. From the argument that next token prediction (for many arbitrary tokens) requires the same information with respect to which embedding belonged to which encoder that inversion does, it is unlikely that any variation of multiple model embedding combination would lead to secrecy (assuming that each model is itself easily invertible).
Training sequences of encoders does not impart secrecy
The structure of LLM architectures today is remarkably homogenous: practically every large model consists of a sequence of modues, each composed of a token mixing layer (usually self-attention or hybrid attention-state space) and a feedforward layer on each token. To simplify this discussion, we refer to the output activations of these modules as ‘layers’. Architectural details are not particularly important for this discussion aside from the sequential nature of models, where the knowledge of one hidden layer (for all tokens) is sufficient to complete the forward pass and get a next token output. This means that the user can retain any first n layers to keep information from the provider, but retaining the last n layers cannot possibly keep information from the provider because they will always be able to simply complete the forward pass.
Arguably the most important effect of the provider always being capable of obtaining know the identity of any output token (if they retain any part of the model at all) is that the provider can trivially assemble a list of non-encoded output tokens for each prompt. This effectively makes KV caching not useful for long conversations, in the sense that the provider is more and more likely to oncover the user’s secrets simply by observing the output tokens produced. The user can circumvent this issue by maintaining many conversations and swapping encoding methods for each next token for each conversation, as then the provider has no knowledge of which conversation corresponds to which input without being able to decode the input. This is notably not the case if KV caching is used, however, as the provider can simply reference the KV vectors they retain to know the identity of the conversation (in terms of output tokens).
Nevertheless, it can be shown that even using sequential architectures can result in perfect (even if impracticaly without KV cache ability) secrecy, and how this can be done is as follows:
First consider an arbitrary sequential model trained for next token prediction, which we call $P$, composed of L layers in total. To share some but not all (or even most) of this model’s information with the user, the provider can send them a certain number of layers starting with the token embedding transformation, which we can think of as an encoder $E = P_{0:n-1}$ while retaining the rest of the layers as a causal decoder $D = P_{n:L}$. In this paradigm, the user takes their message $M$ and encodes it via applying the layers they recieve from the provider to make $e = E(M) \in \Bbb R^{cd}$, where $c$ signifies the context size in terms of the number of tokens $n_{ctx}$ and $d$ the hidden layer dimension, and then sends this encoding to the provider who completes the forward pass and provides the next token to the user.
The encoding $e$ is not strictly speaking in the clear in the sense that one would be able to recover $m$ with no effort, but it is also not a very good encoding for most model types because it can easily be broken. To do so, the provider only has to invert $E$ and can do this by training an inversion decoder $I$ to regenerate inputs given encodings (ie maps $I(e) = M$) in a generalizable way so that practically any natural language input the user provides as $M$ can be recovered, even if it is not in the provider’s training datset. It turns out that this training is not difficult, and takes just a few minues for a small model with $d=512, l=16, c=612$ on the FineWeb-edu dataset. Once the provider has trained their inversion decoder, they can simply take every $e_i$ provided by the user and decode by running a forward pass through the inversion decoder.
The question the user can ask is as follows: can a new encoder be trained such that the provider’s decoder is incapable of accurately mapping the output of this new encoder to the original message $M$? The main constraint here is that thie new encoder, which we refer to as a ‘secret’ encoder $S$, must also be useful for next token prediction and in particular must have a similar next token distribution as the original encoder upon the forward pass of $D$. The answer to this question is ‘yes’, and again fro this secret encoder the provider is able to provide an inversion model.
It may be hoped here that the user could then take the sequences of $S_0, S_1, …, S_n$ and achieve secrecy by selecting one at random, but unfortunately this is not the case: the provider can simply assume that the user has trained these models and invert them all. It can be shown experimentally that this is feasible with very little compute for $n=2$, and there is little reason to suspect that with more compute the ame is not true for larger $n$. Essentially we find that the provider can invert all secret models at once so that mixing and matching these models is not useful for secrecy.
Secrecy with one model
So far we have considered the case in which the provider has trained a model without regards to secrecy, and in particular the model the provider trains is easy to invert over the set of inputs for which one can expect to be able to get a useful output (natural language in our case). It is worth noting that this inversion requires far less compute than actually training the model, and in our experiments requires <1/1000th the pretraining compute. The way we have achieved secrecy in this setting is by using the difference between strict and effective invertibility, which is the difference between a truly invertible function in which each unique inputs maps to a unique output and one that is not invertible in this sense but for which an inversion function can be fitted over all relevant inputs such that for these inputs one can invert the model using this function (this is explained in more detail here). Invertibility and sufficient mixing reflect these definitions: effectively invertible functions are those that may not be truly invertible (as is the case for Transformers generally) but whose embedding space is insufficiently mixed to prevent the training of a learned inverter function.
So far we have examined methods by which an effectively invertible function (a portion of a causal language model) may be modified to become effectively non-invertible if one includes the secret message, and the modification process involves training secret encoders that yield embeddings which both return correct next tokens as well as remove the effective invertibility property of the embedding itself. These approaches make no claims on the model itself, such that practically any off-the-shelf causal language model may be expected to be converted to secrecy. The primary downside to the approaches detailed for this are that they require a significant amount of computation by the user and provider, and a significant amount of communication in the form of gradient vector sharing.
There is much more direct method to secrecy, however: instead of starting with an effectively invertible model and modifying it, we instead perform pretraining of this model in such a way that it is not effectively invertible in the first place. This puts the onus of secrecy on the provider (who has to train a new model) but the secrecy of such a model can be easily verified by attempting to invert the portion shared with the user (which requires a trivial amount of compute relative to the actual pretraining procedure).
Is it possible to train a model that is effectively noninvertible on its ‘encoder’, the first portion of the model that generates the secret embedding $S(x)$ maps token sequence inputs $x \in \Bbb Z^{n}$ to outputs $S(x) \in \Bbb R^{n \times d}$, with the goal that this encoder is generalizable to unseen inputs to be useful for user secrecy?
What do we need to include to prevent a model from being effectively invertible while still performing accurate langauge modeling? Equivalently, how can we train a model to sufficiently mix the input space such that next token prediction is still useful but the output gives little information as to the identity of the input tokens? We start by defining a standard transformer-style causal language architecture as before, and again assume that the provider shares a portion of this model $S$ composed of the first $n$ layers of the full model $O(x, \theta)$ with the user so that they can form $S(M)$. There are two relevant outputs from this model: one is the full forward pass $y = O(x, \theta)$ and another the secret encoder’s output, which we denote $S(x) = O_l(x, \theta)$ for the output at layer $l$. We want to minimize the cross-entropy loss between the full models output and the target sequences, $y, \hat y$, and we train the model to do so. But simultaneously we also want $S(x)$ to be non-invertible, so we also train an inversion model $\theta_I$ that attempts to map $O(S(x), \theta_I)$ to the input sequence $x$ while training the secret model $\theta$ to prevent this mapping.
We perform this training taking inspiration from the competing objective approach popularized by GANs. First we assemble two models: a split encoder/decoder causal language model that maps input tokens to embeddings (at the encoder output) and token predictions (at the decoder output), and a secret decoder model that takes the encoder’s output embeddings as inputs and maps these to the input token sequence. We then perform each training step by alternately optimizing the split encoder/decoder CLM to minimize next token loss (from the decoder) and maximize secret decoder input token matching loss, both via cross-entropy. Then the split model’s weights are updated using this information, but the secret decoder’s weights are frozen (as the secret decoder wants to minimize input token matching loss). In the second phase of each step, the split model’s parameters are frozen and the secret decoder’s weights are updated to minimize the input token matching loss. Freezing and unfreezing weights can be effiently accomplished via toggling gradients in Pytorch with very little overhead.
When this training is performed, we find that the causal model reaches acceptable pretraining loss (cross-entropy loss around 2.9 compared to 2.6 for pure next token prediction models with equivalent compute) and that the inverter model fails to learn an inversion, reaching only 7.3 cross-entropy loss. The next token prediction model is not actually non-invertible, however: if we then fix the CLM and train an inversion model, training proceeds slower perhaps than for standard CLM inversion models but still reaches <0.1 CEL in under 10k training steps. The poor performance of the inversion model trained with the CLM likely results from the CLM updating in such a way that the inverter fails to learn a useful function, but once the CLM is fixed this no longer occurs. This finding holds regardless of the topology of the CLM transformer model (the expansion/contraction between successive MLP layers, number of layers, hidden dimension).
Thus it appears to be very difficult to train a model that is inherently noninvertible over all its inputs, assuming that the inversion function receives all token’s embeddings and is trained with the same dataset as the model and with sufficient compute. This provides more evidence for the idea that for any generalizable function for which no a priori reason exists to suggest effective noninvertibility, with sufficient compute one can indeed perform an inversion.
Secrecy with one model per message: the Tortuga approach
In the last section we considered sequential models and showed how one can perform secrecy obfuscation using combinations of secret encoders. The primary disadvantage of such efforts is that 1) the provider will still be able to obtain the next token, and because of this 2) the secret encoder training method is involved, requiring many models to be trained and utilized.
Happily both of these are features of sequential models rather than language modeling in general. To show that this is the case, consider a counterexample in which a model had a sequential stack of layers similar to current transformers, but a parallel stack (say of many fewer layers) that took as inputs the output of the first layer of the first stack, and gave an output to the input of the last layer. This input can be as simple as a linear combination between layers or else a more complicated operation. In effect this is a model with both sequential and parallel modules, architectures which proved very effective for image modeling in the hands of Google (see GoogleNet).
It is apparent that a provider that retains many layers from such a model typically does not know the identity of the output token, as the output depends on both sequential stacks and the provider may retain only one. This means that the provider does not have knowledge of the user’s next token upon each forward pass, which has the notable advantage of allowing for KV caching to greatly speed up inference.
This property of the provider not knowing the identity of each next token output allows one to train a new type of secrecy system that requires only one model, where the secrecy encoder is more or less unbreakable if the provider does not know the user’s secret message ahead of time. This is somewhat analagous to the island of Tortuga as depicted in the Pirates of the Caribbean movies, where the island can only be found by those who already know where it is (and presumably share the secret as more than one person found the island). In our parlance, the provider can only train a secret inverter model if they know what the secret is.
How can such a secret model be trained? There are theoretical reasons to suppose that any generalizable secret model $S$ (meaning that the user can apply $S$ to any set of messages $M$ and expect for a useful encoding) can be inverted by the provider, the strongest being that the provider only has to guess a corpus that contains $M$ and train inversion models on that corpus because of the generality of $S$ (we assume that there is no a priori reason that $S$ cannot be inverted, for example due to high compression from inputs to outputs). These arguments imply that the user must likely forego a general model if they want to use a single $S$, but happily the alternative can be shown to provide strong secrecy.
The approach to training a secrecy model which is not general to many messages is as follows: first the messages $m \in M$ are selected and then a secrecy encoder $S$ is trained such that the provider’s inversion decoder $D$ is ‘fooled’, and maps $S(m)$ to a random token sequence rather than $m$. This is identical to what was done for general models earlier on this page, but here we limit the number of messages and train to purposely overfit to these few messages. If the provider does now know the identity of these few messages but trains their own secret inverter $D$ knowing this method that the user employed, can they hope to decode $S(m)$? By definition, not if the model is sufficiently overfit to $m \in M$, as the model’s behavior on the inputs that the provider is likely to use for training $D$ do not define the behavior of $S$ on $m$, the inputs that actually matter to the user. Empirically this can be shown as follows: for $\vert M \vert = 64$, each of length $512$ tokens, a provider can generate many (say 10) training runs’ worth of data on a general corpus to train $D$ but when applied to the secret messages $M$ the inversion loss is high, with a CEL of 5.8 and a token reconstruction accuracy of around $12%$.
The user can improve on this general idea by observing that the goal is really to train an $S$ to fool the provider’s secret decoder only on the inputs they care about, and make all the other outputs of $S$ indistinguisheable from the original causal encoder $E_{clm}$. If such a model were trainable, the provider has no hope of recovering $M$ unless they already knew this input because training a secret decoder will result in a model identical to the original causal model inverter. The secrecy of $S(m)$ lies in the ability to be trained to approximate the causal inverter for all inputs except those $m \in M$, so the question remains: can such a model be trained?
Perhaps the simplest way of training this model is to train identically to the causal inversion decoder model for all inputs except for one or a few $m$, which can be simply swapped in to each training minibatch. For those inputs in $M$, $S$ is trained to yield embeddings that give the correct next tokens when fed to the causal language decoder but map to arbitrary random token sequences when fed to the provider’s inverter. This can be done in a similar way as explored above, where a combined causal + inversion objective function is applied to $S$ except that the inversion objective is the true inversion map $S(x_i) \to x_i$ for all inputs not in $M$, where $S(m)$ maps to random tokens. This can be trained to high precision (< 0.01% token reconstruction error) in 1k training steps, and is thus a feasible approach computationally speaking.
Now that we have existence of inputs that satisfy secrecy using this approach, it is worth examining why this is at all possible in the first place. The first consideration here is that the space of large-dimensional models is huge, and there are features of these spaces (notably rapid mixing) that all but ensure one can find a point (embedding) that satisfies the properties above.
Tag-based Secrecy for Generalizable Noninvertibility
The one-model-per-message approach detailed in the last section is not very efficient, as a user would have to train a new encoder for each secret message or set of messages. Happily the approach can easily be modified so that this is not the case by simply introducing a unique sequence before each secret message, rather than relying on the uniqueness of the message itself. This unique sequence tag is analagous to a secret key, that generates the encryption function (the overfitting-trained secret encoder) and must be kept secret from the provider.
Now consider what this secret encoder is trained to do: it maps all inputs without a tag, or without the correct tag, to points that are identical to those from the original encoder with respect to model inversion, but for inputs with the secret tag the resulting inputs are mapped to a random sequence by the original encoder’s inverter. Can an arbitrary secret encoder be inverted by an inversion model trained to generalize to any given random sequence? If the training process results in a sufficiently unique model for each and every tag, the answer is no for the same reason that the Tortuga approach is non-invertible, specifically because the provider must guess the exact secret sequence in order to train an inversion model.
The question of whether this tagging method imbues secrecy therefore reduces to the question of whether the secrecy encoder training (with tags and a random inversion target per tag) results in sufficiently unique models for each tag. This can be tested in the same way that a provider would seek to break the secret encoder: by training many secret encoders (each with an associated tag and inversion target), obtaining the embeddings and corresponding inputs from these models, training a secret decoder inversion model, and observing the secret decoder’s generalization to embeddings generated using unseen (secret) tags and input token sequences. If tags provide sufficient uniqueness, we expect to see that the secret decoder cannot generalize to samples with unseen tags.
For clarity the random tag-based training procedure may be summarized in the following figure:
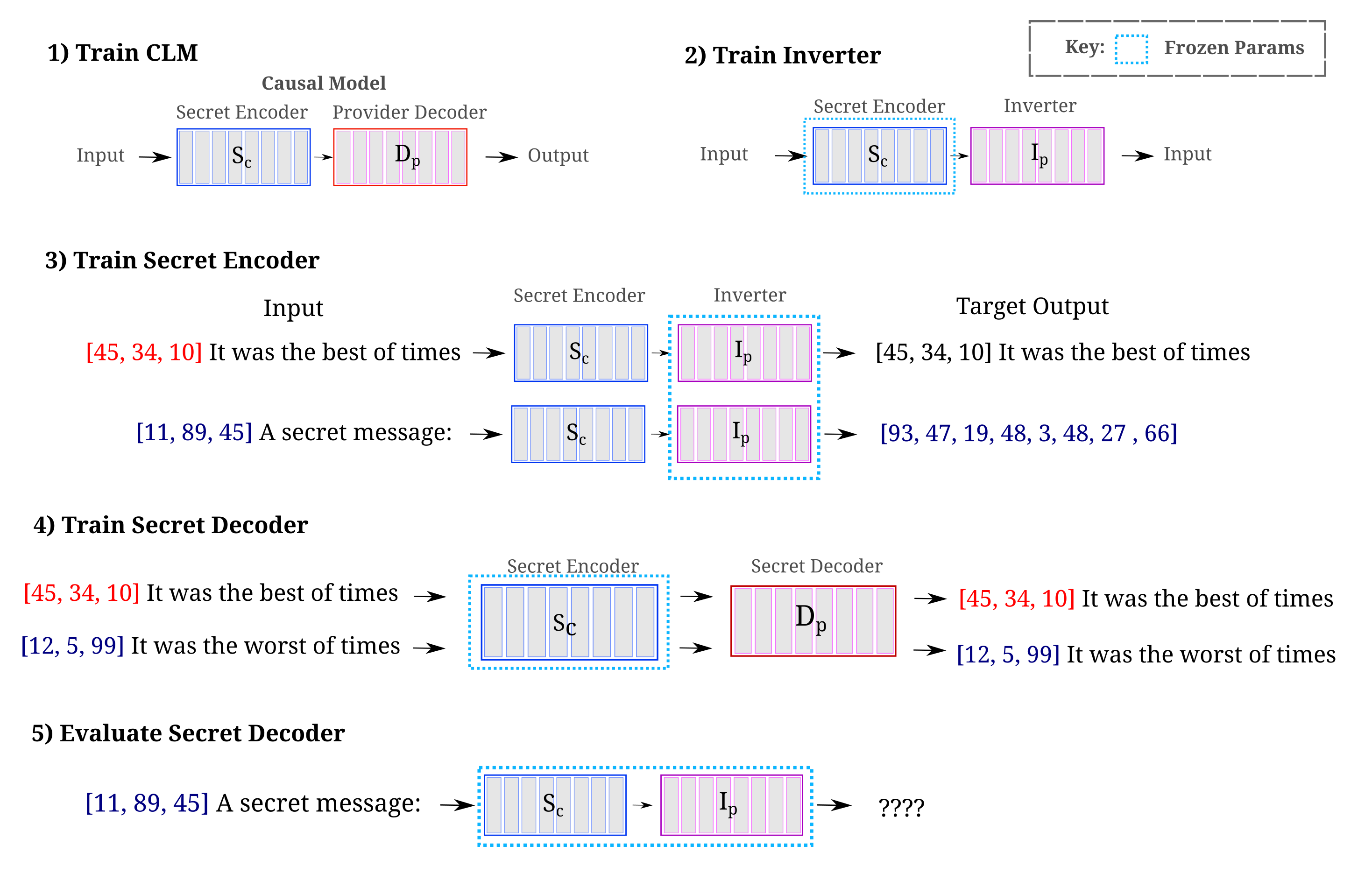
Recalling that without secrecy training data from a single encoder model yields near-perfect inversion decoder accuracy, and that samples from fewer than 10 secret models yield near-perfect accuracy for inherently generalizable secret encoders, we find the minimum hold-out evaluation (tagged secret message) loss and token accuracy of the secret decoder inversion model given samples from a variable number of trained secret encoders:
| Number of $S_n$ | Cross Entropy Loss | Token Accuracy |
|---|---|---|
| 10 | 6.50 | 0.115 |
| 100 | 6.07 | 0.168 |
| 400 | 5.60 | 0.190 |
| 1000 | 5.27 | 0.199 |
A natural question to ask is whether the size of the secret tag affects the invertibility of the embedding. This can be tested by increasing the number of tokens used for the secret tag by a factor of 10 (to 100 tokens) and repeating the above scaling experiment. The results are given below, and as one may expect there is indeed a decrease in inversion model accuracy with a larger secret tag, but the accuracy gap shrinks as the number of secret models trained increases. This results in the following:
| Number of $S_n$ | Cross Entropy Loss | Token Accuracy |
|---|---|---|
| 10 | 7.21 | 0.089 |
| 100 | 6.52 | 0.118 |
| 400 | 5.71 | 0.167 |
| 1000 | 5.33 | 0.192 |
Another question is whether the secret model’s random target for $D_I$, the vector where each element is drawn from a uniform distribution, $y \in \mathcal U$, is actually ideal for secrecy. In particular, would an in-distribution target (drawn from token sequences in dataset inputs) result in lower secret decoder accuracy? Experimentally no, as for example with $\bar S_n \bar = 10$ an in-distribution tag results in a CEl of 6.44 and token accuracy of 0.126.
These results support the idea that the use of secret tags and random inversion targets imparts noninvertibility properties on any tagged input, and in that way generalizes to any input that the user wishes to remain secret. This is the first method investigated on this page to do so, and suggests that there does exist a method by which a user can enforce secrecy in a generalizable way, where the provider cannot learn an inversion model even if they know how the user’s model is trained. The necessary component of this method is the tag itself, which effectively creates a unique dataset that the user can access but remains hidden from the provider.
Noninvertibiliy training by itself is not particularly useful for language modeling as there is no guarantee that the resulting embeddings will yield accurate next tokens. Next token accuracy may be trained by finding the cross-entropy loss between the original model’s predicted next tokens and the noninvertible model’s predicted next tokens, which involves sending embeddings from user to provider and receiving gradients back. Noninvertibility training is clearly a prerequisite in order to ensure that the provider cannot simply take these embeddings and invert them. The gradient generation process here compares provider decoder outputs given invertible to noninvertible (original model) embeddings to the (shifted) actual output, with the optimization goal being to maximize the likelihood of correct next token prediction. Alternatively, one can compare the tokens predicted by the noninvertible embeddings to those predicted by the original model and minimize that distance, but this process cannot be done without sharing the (secret) input with the provider as the original model’s embedding is assumed to be invertible.
As noninvertibility training (via tagged inputs or otherwise) typically results in embeddings that have poor next token prediction power, one must follow noninvertibility training with next token prediction training to ameliorate this issue. If this is done for many inputs for generalizable modeling, however, there turns out to be a drastic increase in the ability of a provider’s secret decoder to learn to decoder the original input: for example, for data from 10 models the secret decoder’s input token accuracy increases from 11.5% for inversion training only to 74.8% with inversion training followed by next token prediction training (in this case training to match the original model’s next token predictions).
If we only train to predict next tokens for one or a few samples, however, there is much less increase in secret decoder accuracy (16.3%) that corresponds to poor next token prediction in held out samples. This once again demonstrates the tradeoff between generalization and invertibility, in this case we effectively overfit the encoder to produce usable embeddings (with respect to next token prediction) only for a relatively small set of secret messages, and no other inputs.
Secrecy Accessory Models for Language Modeling
In the last section we saw that one can train an encoder to be effectively noninvertible using the random tag overfitting training approach, but that if one then further trains these models to perform causal language modeling (next token prediction) they are much easier to invert, unless the models are trained to predict tokens from only one or a few sequences.
Happily there is another way to re-train a secret model for next token prediction: to avoid modifying the secret (noninvertible) encoder, the user adds modules to the provider’s model and trains these for next token prediction, so that the provider obtains only the secret embedding, sends the decoder’s output to the user, and the user then trains modules to convert this output to one that is useful for next token prediction. We find experimentally that training accessory modules like this is more efficient if the user includes a small encoder in parallel to the secret model encoder/provider decoder as shown below:
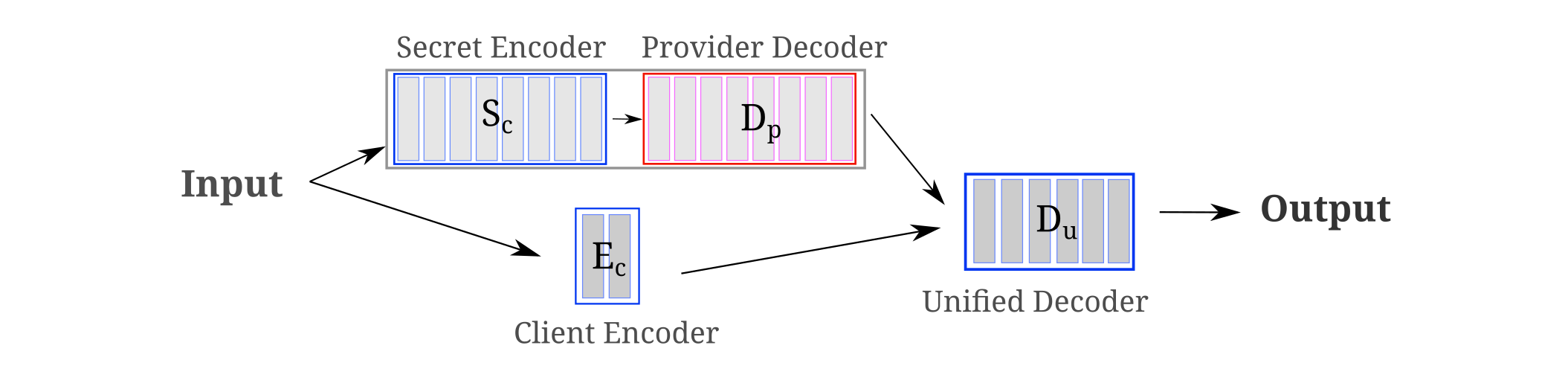
We can train the above architecture as follows: first $S_c$ is trained to be noninvertible via the random tag overfit approach, and then it is frozen (along with $D_p$) and $E_c$ and $D_u$ are added and trained for next token prediction, either by minimizing cross-entropy loss to the shifted token sequence or the unshifted original model’s output sequence. When this is done, we find that training the accessory modules requires more steps (~8k) than the secret model (300), but that the model does learn to recapitulate the original model’s next token prediction accuracy. As the provider recieves the same secret encoding as before the accessory modules were added, the provider can no more invert the secret embedding than they could before the model was re-trained for next token prediction. Furthermore, the provider does not have to receive any gradients during the accessory module training process (as the provider decoder and client encoders are both frozen) so the provider cannot get information from the client’s training gradients either.
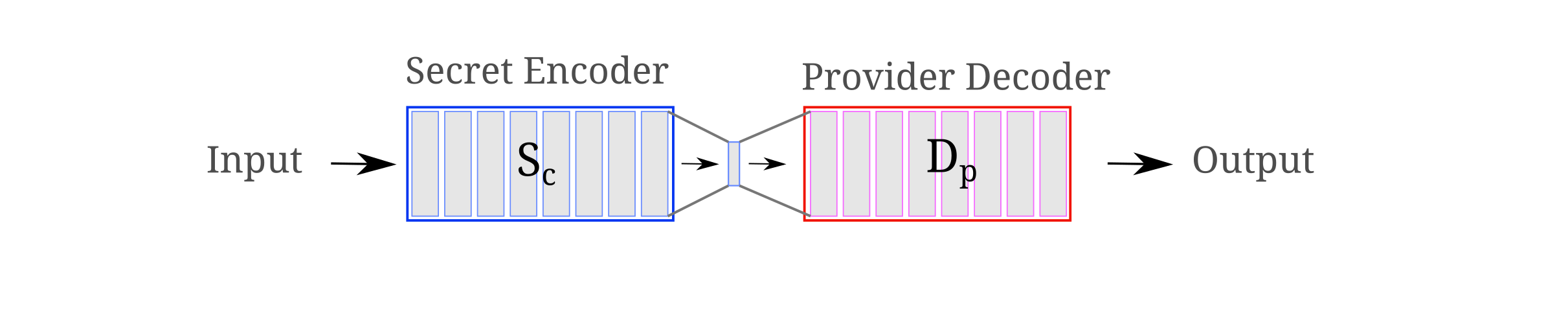
It is also natural to wonder whether adding a noninvertible transformation to the user encoder (see the following figure) would increase secrecy strength. It is worth noting that simply adding a noninvertible transformation does not prevent effective inversion where a model learns to invert inputs from a finite dataset: for example, adding a $f: \Bbb R^{512} \to \Bbb R^{32}$ transformation mid-way through the model stack (just before the embedding layer sent to the provider) results in a relatively mild decrease in causal training efficiency, with 2.64 CEL with compression versus 2.57 CEL without for 13B tokens trained on FineWeb. Including this transformation does not prevent inversion on those embeddings in the slightest (this can still be trained in a few thousand steps to high >99.9% precision), but does it help the random tag overfit training procedure?
We find that it does indeed: for the same model presented previously, we repeat the random tag secrecy training procedures for many tags and profile the ability of an inversion model to decode the secret embeddings. We find that the loss achieved by this secret decoder rapidly plateaus (below), with little indication that very large increases in the sample size (up to the size of the secret tag, that is) would benefit this model’s training. This means that even if the provider wished to generate billions of $S_n$, there is no reason to think that a secret decoder trained on samples from all these models would be capable of generalizing the the user’s model with its secret tag. Of course, if the provider were to train every possible secret model then they would be able to decode the secret embedding, but doing so would be prohibitively compute expensive as even our modest tag size of 10 tokens (with an 8k size tokenizer) would require training $8000^{10} > 1 * 10^{39}$ models, and as training 1k models requires approximately 24 hours of H100 time the provider would have to be able to access around $2.5 * 10^{37}$ hours or around $1 * 10^{33}$ years of H100 time, a clearly impossible task given that it would take a supercluster of 100k H100s around $1*10^{28}$ years, which is much more than the current age of the universe.
| Number of $S_n$ | Cross Entropy Loss | Token Accuracy |
|---|---|---|
| 10 | 6.92 | 0.130 |
| 100 | 6.81 | 0.141 |
| 400 | 6.77 | 0.152 |
| 1000 | 6.80 | 0.154 |
It is also natural to wonder whether or not this approach (overfitting random tag training for noninvertibility followed by accessory model training for causal language modeling recovery) is only computationally feasible for small models, or if it can be applied to much larger models without increasing the burden of training on the user. In particular, it could be wondered whether or not the causal recovery training is only possible because the accessory modules are trained within an order of magnitude of (specifically 1/20th) the compute used to pretrained the original causal model, and whether that would be necessary for larger models trained with far more compute.
To investigate this question, we repeated the overfit tag secrecy training method with Llama 3.2 1b, which is around 15x the size and was trained with perhaps 50,000x the compute and 1,000x the data as the small FineWeb-trained transformer used elsewhere on this page. We found that training an inversion model required only slightly more (1.5-2x) the compute for Llama 1b as for our small model, and the same for secret tag overfitting training with respect to this inversion model. Before tag overfit training, Llama 3.2 achieves ~0.95 CEL with respect to its original predicted tokens, and it requires only 3.5k steps (rather than ~8k as for the small model) or ~56k sequences to reach this loss upon training to recover next token prediction using the same architecture noted above, which comes out to near-equivalent FLOPs as for the small model. This is strong evidence that pretraining scale does not affect the amount of data or compute required to ‘undo’ the noninvertibility training changes to a large model, but that this is balanced to the inversion training itself. As noninvertibility training is not substantially more difficult for large models, it stands to reason that this method could be applied to frontier models (typically with >1T parameters today) with a small increase in the user’s compute and data requirements.
Thus the burden of training a secret encoder to become effectively noninvertible does not scale with the original CLM’s size and compute spent on training, nor does the burden of training a decoder to convert the provider’s encoder back to a useable token prediction.
Recap
Returning to our original question: can a user, who wants to keep most of a message secret, and an LLM provider, who wants to keep most of their model’s parameters secret, successfully undergo langauge modeling and get a next token while sharing only a small portion of their respective information? We have seen that the answer to this question is yes (assuming that the provider and user work together), and that this is the case both when the provider trains a model with secrecy in mind (such that it is effectively non-invertible) and somewhat surprisingly is also the case when the provider’s model was not trained for secrecy (and is easy to invert under normal circumstances), with somewhat less practical implementations.
How does this procedure relate to public key cryptography? It is in many ways closely analagous, and we can equate each component as follows: the secret key is equivalent to the secret tag prepended to the secret message, the public key and encryption method are bundled together as the secret encoder, the secret encoder’s output is the encrypted message Alice sends to Bob, the provider’s output given this secret encoder output as an input is simply a usefully transformed encryption, and the client’s CLM accessory modules are the decryption method.
Both public key cryptography and this language model secrecy method rely on one-way functions (easily computable, not easily invertible) for secrecy. The process of secret encoder training defines this one-way function for the language modeling case, and this relies on the encoder learning via overfitting to the secret key so that the model’s properties do not generalize to arbitrary keys. Perhaps the most surprising aspect of secrecy training is that this encoder’s embedding is capable of yielding useful outputs from the provider’s decoder, assuming that these outputs can themselves be decoded by the client. The main reason we may expect for this to be possible in the first place is the enormous size of language model hidden states, such that there exists multitudes of equivalent regions that are difficult to find but yield similar characteristics for a given forward pass.
Redaction Secrecy
It is frequently the case that only part of a secret message is truly secret, in the sense that there are some words or for language models tokens that exist in the secret message but that are not essential to keep secret. We can modify the original assumptions of secrecy applied to language modeling above to capture this case by assuming that the user has identified the subset of tokens that must remain secret, and can provide secrecy by simply masking these tokens and retaining information locally. For a carefully designed parallel architecture, doing so results in the provider never accessing any redacted information at any step, and therefore secrecy of the redacted information is almost trivially guaranteed if the user simply redactes any output tokens necessary as they are generated. The questions of whether such a model may be efficiently trained and how much redaction can feasibly be performed before the provider’s embedding becomes superfluous are addressed here.
Perfect Redaction Secrecy Design
As stated above, the user can betray no redacted information (beyond what is present in the non-redacted tokens) by simply replacing redacted inputs with a special token and sending the resulting token sequence to the provider, while keeping the undredacted token sequence for processing by the local portions of the model. One relatively straightforward architecture for this is as follows: the model consists of three modules, the user encoder, provider encoder, and combined decoder, where the encoders map token sequences to embedding sequences and the decoder maps both embedding sequences to output tokens. This architecture is represented in the following diagram, for the case where the provider’s model consists of 16 transformer layers, the user (client) encoder 3 layers, and the unified decoder 4 layers:
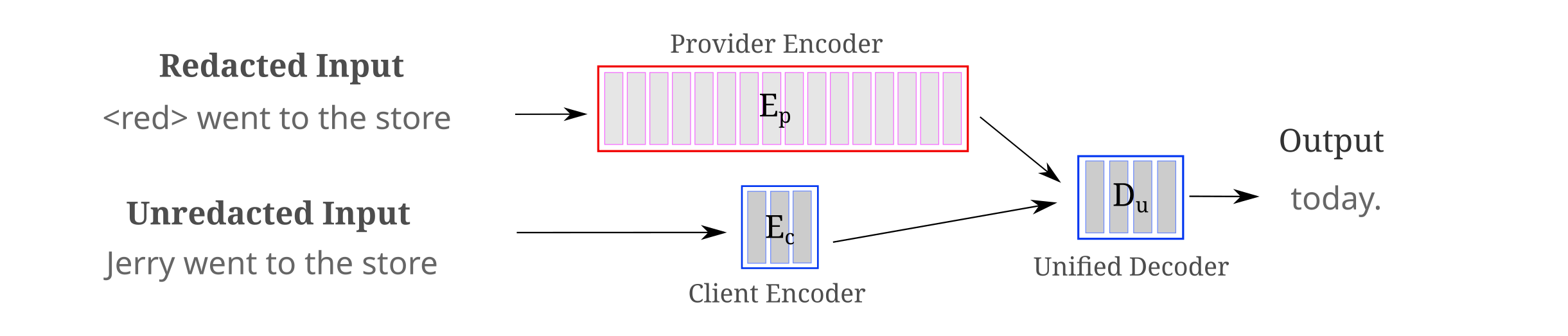
This approach is relatively computationally efficient for the user: it has the added benefit of requiring only one relatively slow network transfer step (embeddings sent from provider to user), which also has the benefit of being well matched with the usual pattern of higher download to upload speeds provided by non-fiber interconnect. The user’s computation to compute $E_c(x)$ occurs asynchronously to the provider’s (much larger) computation of $E_p(x)$ and the provider’s relatively heavy network embedding transfer to the user over the network. Assuming the user caches embeddings, the provider needs to send only one embedding to the user.
We cannot include hidden layer mixing operations such as cross-attention between user and provider modules as these may send redacted information to the provider, but rather the user and provider encoder forward passes must be completely independent. The information mixing step occurs when the embeddings of these encoders is combined, but how can this be done most effectively? We investigated three approaches: a linear combination, an MLP layer applied per token, and cross-attention.
A linear combination is as follows: each token embedding is of shape $E(x) \in \Bbb R^{n \times d_m}$, and we can simply add each token’s embedding from the two encoders to make $aE_p(x) + bE_c(x) = E(x) \in \Bbb R^{n \times d_m}$. A simple MLP implementation is to concatenate embeddings in the embedding dimension to form $E_p(x) \circ E_c(x) = E(x) \in \Bbb R^{n \times 2d}$ and then define a linear transformation $M: \Bbb R^{2d} \to \Bbb R^d$ as our MLP. We find that models with linear combinations where $a=b=1$ (2.752 eval CEL at 200k steps for 90% redactions) empirically train with nearly identical efficiency (2.747 eval CEL at 200k steps again for 90% redactions) to this MLP implementation. Cross attention is commonly implemented by obtaining query projections from one hidden layer and key and value projections from another, and as we know that the output of $E_c(x)$ contains all the information we need it is reasonable to use this as the key/value source and $E_p(x)$ as the query source, and we normalize. We observe somewhat lower efficiency (3.250 CEL for cross-attention without versus 3.177 CEl for cross-attention with layernorm on output versus 3.079 CEL for a linear combination at 12k steps) than the linear projection with higher compute required per step.
The next question to address is whether or not such an architecture may be efficiently trained. We find that these models are indeed efficiently trainable as long as the proportion of redacted tokens to all tokens is well under a half. In the following table, we observe final losses as follows:
| Percent of tokens redacted | Cross Entropy Loss |
|---|---|
| 0 (CLM only) | 2.573 |
| 5 | 2.596 |
| 10 | 2.632 |
| 20 | 2.678 |
| 30 | 2.678 |
| 40 | 2.729 |
| 50 | 2.734 |
| 90 | 2.742 |
| No Provider | 2.746 |
Redaction Secrecy with Pretrained LLMs
It is illuminating to consider the question of whether or not a pretrained LLM (trained for next token prediction without redaction, that is) can be used as the provider’s encoder, or whether it is necessary to train such a model from scratch. We find that pretrained models are indeed relatively efficiently incorporated into a redaction-style secrecy architecture…